
Most conversations around agentic AI stay abstract—full of concepts, light on implementation. But for teams operating real data systems, the question is practical:
How do you evolve an existing pipeline-based system into something adaptive, without breaking scale and reliability?
The answer is not replacement. It is recomposition.
⸻
The Reality: Pipelines Are Still the Foundation
Most organizations today already have robust systems in place—data ingestion pipelines, ETL workflows, feature engineering layers, model pipelines, and dashboards. These systems are designed for scale. They are reliable, optimized, and efficient for repeated computations.
But they share a fundamental limitation: they are static.
They answer predefined questions, not evolving ones. Every new question often requires new engineering effort—new transformations, new jobs, or new dashboards.
⸻
Why Pure Agentic Systems Don’t Work
A common instinct is to replace pipelines entirely with agents—letting an LLM dynamically fetch, process, and compute everything on demand.
In practice, this fails quickly.
Large-scale data cannot be recomputed per query without unacceptable latency. Costs increase dramatically. Outputs become inconsistent because the system lacks structure. Most importantly, reliability degrades.
Pure agentic systems are not designed for heavy data workloads.
⸻
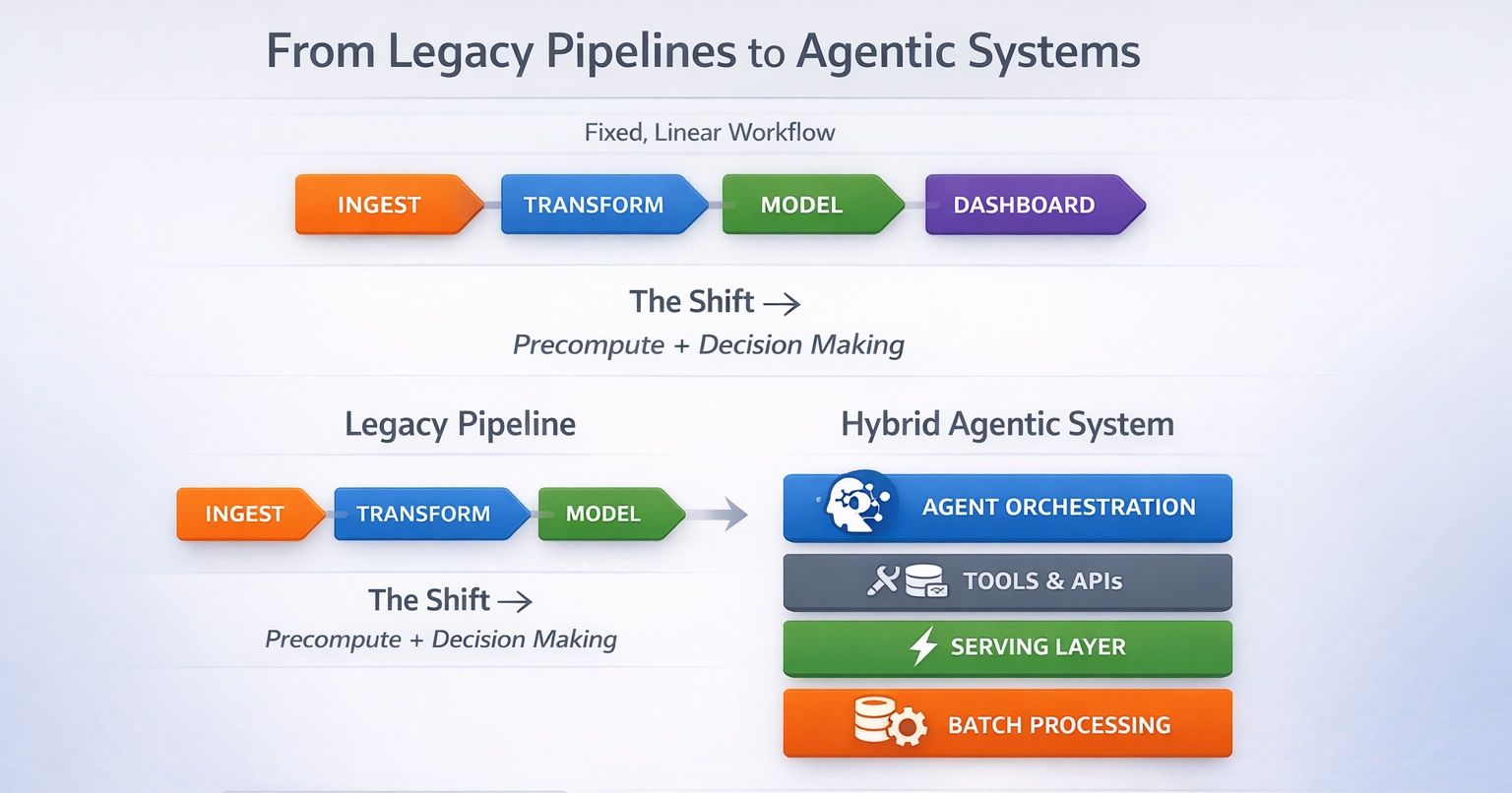
The Hybrid Architecture That Works
The systems that are succeeding combine the strengths of both approaches.
They retain pipelines for heavy lifting, but introduce a new layer that makes those pipelines dynamic and queryable.
The architecture looks like this in essence:
- A batch layer handles precomputation
- A serving layer ensures low-latency access
- A tool layer exposes capabilities
- An agent layer orchestrates execution
This is not a replacement—it is an evolution.
⸻
Refactoring Pipelines Into Capabilities
The first step is not to remove pipelines, but to refactor their outputs into interfaces.
Batch jobs, feature computations, and data warehouse outputs remain intact. What changes is how they are accessed.
Instead of being buried inside DAGs, they are exposed as callable capabilities—functions that can be invoked with parameters.
This transforms pipelines from rigid flows into reusable building blocks.
⸻
Introducing a Tool Layer
Once capabilities are exposed, they form a tool layer.
Each tool represents a single, well-defined operation—fetching data, computing features, running a model, or applying a transformation. Tools are stateless, with clearly defined inputs and outputs.
The goal is not to create new logic, but to wrap existing systems in a way that makes them composable.
⸻
Adding an Agent Layer (Carefully)
The agent layer sits on top of these tools. But its role is often misunderstood.
It is not there to compute everything.
Instead, it decides:
- which tools to use
- in what sequence
- whether existing data is sufficient
- when additional computation is required
This turns execution from a fixed pipeline into a decision-driven process.
⸻
The Need for Explicit Decision Policies
One of the biggest gaps in naive implementations is the absence of a decision policy.
Without it, agents behave unpredictably—overusing tools, recomputing unnecessarily, or ignoring available data.
A production system must explicitly define:
- when to use precomputed data
- when to refine existing outputs
- when to trigger recomputation
This is where control is reintroduced into an otherwise flexible system.
⸻
Progressive Computation: Controlling Cost and Latency
A key principle that emerges in practice is progressive computation.
Instead of jumping to full recomputation, the system escalates:
- Start with precomputed summaries
- Refine using filters or adjustments
- Perform targeted recomputation if needed
- Only rarely trigger full pipeline execution
This ensures that most queries remain fast and cost-efficient, while still allowing flexibility when required.
⸻
Structuring the System: Nodes and Tools
To maintain clarity, the system benefits from separating execution and capability.
Tools represent capabilities—reusable operations over data or models.
Nodes represent execution units—stateless components that take input, apply logic (possibly using tools), and produce output.
Some nodes are deterministic. Others, especially LLM-driven nodes, introduce decision-making and can dynamically select tools.
This separation keeps the system modular, testable, and extensible.
⸻
What Changes for Data Teams
The role of data teams evolves significantly in this model.
Previously, the focus was on building and optimizing pipelines. Now, it shifts toward:
- designing clean interfaces for capabilities
- defining boundaries between precomputed and dynamic computation
- ensuring composability of systems
The emphasis moves from building flows to enabling decisions.
⸻
Where the ROI Comes From
The benefits of this architecture are not theoretical—they show up directly in system efficiency and team productivity.
Compute costs are reduced because unnecessary recomputation is avoided. Time-to-insight improves because new questions no longer require new pipelines. Existing infrastructure is better utilized, as previously siloed systems become accessible through tools.
Most importantly, workflows that previously required manual coordination can now be orchestrated automatically.
⸻
What to Avoid
Several patterns consistently fail in practice.
Exposing all tools to every agent creates confusion and poor decisions. Allowing agents to recompute everything leads to cost and latency issues. Removing batch pipelines breaks scalability. Over-abstracting model differences reduces control and reliability.
The system must remain structured, even as it becomes more flexible.
⸻
The Resulting Architecture
At a high level, the system resolves into a layered design:
- A data layer (ETL, warehouse)
- A precompute layer (batch processing)
- A tool layer (capabilities as APIs)
- An agent/orchestration layer (decision-making)
- The user or system interface
Each layer has a clear responsibility, and the interaction between them is explicit.
⸻
Final Takeaway
The future of data systems is not a choice between pipelines and agents.
It is a combination of both.
Pipelines provide scale and efficiency. Tools provide access and modularity. Agents provide adaptability and intelligence.
The shift is from defining workflows to defining capabilities—and letting systems compose them dynamically.